
This article will focus on the Naïve Bayes Classification method of analysis.
What is Naïve Bayes Classification?
Naive Bayes is a classification algorithm that is suitable for binary and multiclass classification. It is a supervised classification technique used to classify future objects by assigning class labels to instances/records using conditional probability. In supervised classification, training data are already labeled with a class. For example, if fraudulent transactions are already flagged in transactional data and if we want to classify future transactions into fraudulent/non fraudulent, then that type of classification would be called supervised.
Let’s say we want to classify fruit. Fruit may be considered to be an apple if it is red, round, and about 3″ in diameter. If we have data on 1000 pieces of fruit including features or characteristics of each fruit, we can classify the 1000 pieces of fruit characteristics such as shape, length, color, sweet, sour, etc.
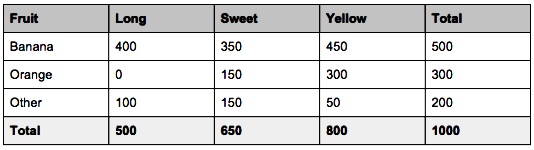
When we look at the table above, we see that: 50% of the fruits are bananas, 30% are oranges, 20% are other types of fruits.
The Naive Bayes classifier assumes that every feature/predictor is independent, which is not always the case, so it is important to understand the type of data you are analyzing before choosing this, or any other, analytical technique.
In order to make the best use of the Naïve Bayes method, the training dataset should be adequate enough to represent the entire population – containing every combination of class label and attributes. Naïve Bayes performs well in cases of categorical input variables compared to numerical variables. For numerical variable, normal distribution is assumed which is a strong assumption.
How Can Naïve Bayes Be Used for Enterprise Analysis?
This technique can be useful in evaluating many applications.
- Weather Forecasting – Based on temperature, humidity, pressure etc., an organization can predict if it will be rainy/sunny/windy tomorrow.
- Fraud Analysis – Based on various bills submitted by an employee for reimbursement for expenditures on food, travel, etc., a business can predict the likelihood of fraud.
Use Case – 1
Business Problem: A bank loans officer wants to predict if a loan applicant will be a bank defaulter or non defaulter based on attributes such as loan amount, monthly installment, employment tenure, the number of times delinquent, annual income, debt to income ratio etc. Here the target variable would be ‘past default status’, and the predicted class would contain the values ‘yes or no’ representing ‘likely to default/unlikely to default’ class respectively.
Business Benefit: Once classes are assigned, the bank will have a loan applicant dataset with each applicant labeled as “likely/unlikely to default”. Based on these labels, the bank can easily make a decision on whether to give a loan to an applicant and how much credit and interest rate each applicant is eligible to receive.
Use Case – 2
Business Problem: A doctor wants to predict the likelihood of successful treatment of a patient disease or condition based on various attributes of a patient such as blood pressure, hemoglobin level, blood sugar level, the name of a drug given to the patient, the type of treatment given to patient etc. Here the target variable would be ‘past cure status’ and the predicted class would contain values ‘yes or no’ meaning ‘prone to cure/ not prone to cure’ respectively.
Business Benefit: Given the health and body profile of a patient and recent treatments and drugs administered, the probability of a cure can be predicted and changes in treatment and drug recommendations can be suggested if required.
The Naive Bayes is a classification algorithm that is suitable for binary and multiclass classification. Naïve Bayes performs well in cases of categorical input variables compared to numerical variables. It is useful for making predictions and forecasting data based on historical results.
The Smarten approach to augmented analytics and modern business intelligence focuses on the business user and provides tools for Advanced Data Discovery so users can perform early prototyping and test hypotheses without the skills of a data scientist. Smarten Augmented Analytics tools include assisted predictive modeling, smart data visualization, self-serve data preparation, Clickless Analytics with natural language processing (NLP) for search analytics, Auto Insights, Key Influencer Analytics, and SnapShot monitoring and alerts. These tools are designed for business users with average skills and require no specialized knowledge of statistical analysis or support from IT or data scientists. Businesses can advance Citizen Data Scientist initiatives with in-person and online workshops and self-paced eLearning courses designed to introduce users and businesses to the concept, illustrate the benefits and provide introductory training on analytical concepts and the Citizen Data Scientist role.
The Smarten approach to data discovery is designed as an augmented analytics solution to serve business users. Smarten is a representative vendor in multiple Gartner reports including the Gartner Modern BI and Analytics Platform report and the Gartner Magic Quadrant for Business Intelligence and Analytics Platforms Report.
 Augmented Analytics, Data Literacy, Fraud Analysis, Naïve-Bayes Classification, Training for Citizen Data Scientist, Weather Forecasting
Augmented Analytics, Data Literacy, Fraud Analysis, Naïve-Bayes Classification, Training for Citizen Data Scientist, Weather Forecasting
Other posts







